Apurva MisraHow do I make my for loop faster? - Multiprocessing & Multithreading in PythonHow often do we have to run a compute-heavy operation on a list of objects? or read a list of files from a storage space like S3?4 min read·May 4, 2022----
Apurva MisrainAnalytics VidhyaThree pillars of a “good” software productHow many times has it happened that your manager mentioned terms like SLA or SLO and it went over your head?6 min read·Jan 21, 2022----
Apurva MisrainAnalytics VidhyaSpellChecker: Everything you might want to know“why are they not picking theer bags?”5 min read·May 12, 2021----
Apurva MisrainAnalytics VidhyaStatistical musings- part II am a data scientist and an avid reader of books ranging from biographies to statistics. The most important learning from these books is…6 min read·Dec 14, 2020----
Apurva MisrainAnalytics VidhyaTopic Modeling: How the news has shifted from the Coronavirus to Black Lives MatterThe ongoing BLM protests have caused a shift in the news coverage from the coronavirus to racism, which made me curious to look into how…5 min read·Jun 28, 2020----
Apurva MisrainAnalytics VidhyaChoosing the best ones: Feature Selection“Feature Importance”, “Feature Selection” are different phrases meaning the same thing- finding the features which contribute the most…4 min read·Jun 11, 2020--1--1
Apurva MisrainAnalytics VidhyaTweets: You can’t hit unsend (sentiment analysis and web scraping)“Tesla shares tank after Elon Musk tweets the stock price is ‘too high’ ”, was one of a recent headline even after the previous court…4 min read·May 23, 2020--1--1
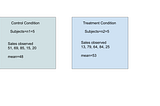
Apurva MisrainAnalytics VidhyaHypothesis Testing with PythonWe will start with a brief overview about the idea and then move over to the variety of tests and try to include an example to work with…3 min read·May 11, 2020----
Apurva MisraStat tests when you don’t know what the distribution is- Permutation/Randomization TetsLet’s first start with the use of Statistical tests with the help of an example-3 min read·May 31, 2019----